Service Resilience means that when the service’s operating environment has problems, such as network failure, service overload or some microservice downtime, the program can still provide some level of the services. Then, we say that the service is resilient. It is a very important part of Microservices and is widely discussed. It improves the quality of a service by improving the resilience of services to compensate for environmental deficiencies.
Service Resilience Improves the reliability of services through the following technologies:
- Timeout
- Retry
- Rate Limiting
- Circuit Breaker
- Fault Injection
- Bulkhead
Code Implementation:
Service resilience can be achieved in different ways, let’s implement it in code first. The program is not complicated, but the problem is that the code of service resilience is mixed with the business code, which brings the following problems:
- Incidentally changing business logic: When modifying the code of service resilience, you may incidentally change the business logic.
- The system architecture is not flexible: It will be difficult to change to other architectures in the future. For example, if you switch the implementation from coding to infrastructure, then you need to extract the code of service resilience from business logic code, which will be troublesome.
- Program readability is poor: Because the code of business logic and non-functional requirements are mixed together, it is difficult to understand what functionality this program is trying to accomplish. Because you read the code a lot more than change it, this is a fatal problem.
- Increase the burden of testing: Whether you want to modify business logic or non-functional requirements, you have to carry out regression testing, which drastically increases the testing burden.
In most cases, we already the business logic in place and want to add the above mentioned features later, and we don’t want to modify the business logic code. The pattern we used is called the Decorator Pattern. In Go, it is also called the Middleware Pattern. The key to the Decorator Pattern is to define a set of decorators and each of them accomplishes a different feature, and their return types (which are Interfaces) are the same, so we can chain these decorators together.
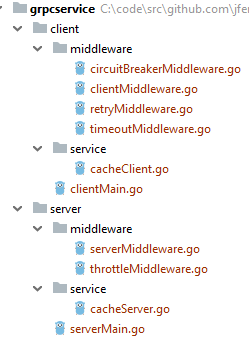
We use a simple gRPC Microservice to demonstrate the functionality of service resilience. The following diagram is the program structure, which is divided into client side and server side, and their internal structure is similar. The “middleware” package is a package that implements the service resilience features. The “service” package implements the business logic. On the server side, the “service” package contains code of the business logic of the microservice. On the client side, the “service” package contains the functions that call the server. The “middleware” package under the “client” package contains four files, which implement three functions: service timeout, service retry, and Circuit Breaker. “clientMiddleware.go” is the entry point. The “middleware” package under the “server” package contains two files, which implement one function, rate limiting. “serverMiddleware.go” is the entry point.
Decorator Pattern:
There are different implementations of the Decoration Pattern. The one I used is from Go kit. It is the most flexible implementation of the Decorator Pattern I have seen.
Below is the “cacheClient.go” in the “service” package, which is used to call the server function. “CacheClient” is an empty structure to implement the “CallGet()” function, which implements the “callGetter” interface (described below). It is the main function (the rest are decorators) in the pattern and includes all the business logic.
|
|
The following is the client’s entry file “clientMiddleware.go”. It defines the “callGetter” interface, which is the core of the Decorator Pattern, and all decorators must implement this interface. There is only one function “CallGet” in the interface, which will be called by each decorator to pass the control to the next decorator. The signature of this function is defined by the business function. It also defines a struct “CallGetMiddleware”. There is only one member “Next” in it, and its type is the decorator interface (callGetter), so we can call the next decorator with “Next”. Each decoration function has a corresponding decorator struct, so we can chain them together to complete all the decoration functions.
“BuildGetMiddleware()” is used to chain decorators together. “CircuitBreakerCallGet”, “RetryCallGet”, and “TimeoutCallGet” are the implementation struct of Circuit Breaker, service retry, and service timeout, respectively. They also have only one member “Next” in each of them. Pay attention to the order when creating them. The first created, “CircuitBreakerCallGet”, will be executed last. At the end of each decorator, “Next.CallGet()” is called, which passes control to the next decorator.
|
|
Service Retry:
When the network is unstable, the service may temporarily fail. This situation usually lasts for a short period of time and can be fixed by simply retry. The following is the program. Its logic is relatively simple. If there is a failure, it will keep calling “tcg.Next.CallGet(ctx, key, csc)” until the result is correct or the retry limit is reached. There is a retry interval (retry_interval) between each retry.
|
|
The difference between service retry and other features is that it has a lot of side effects, so use it with care. Because retrying can significantly increase the system load, and even bring it to a halt when there is a cascading effect. Please carefully choose the following two control parameters:
- Number of retries: Generally speaking, the number of retries should be limited to a small number to reduce system burden.
- Retry interval: The retry interval should increase with the number of retries, because with the number of retry increase, the possibility of failure increase too. You can use a Fibonacci sequence or exponential number and also introduce some randomization strategy to avoid collision. Of course, if the number of retry attempts is small, it may not need that complexity. In the example, the simplest strategy, constant interval is used, which is best not to be used in a production environment.
Not all functions need retry feature, only important ones, which can’t fail.
Service timeout
The service timeout sets a maximum time limit for each service. After the service is timeout, an error message is returned. First, it can reduce the user waiting time, because if a normal operation does not produce results after a few seconds, there is no reason to wait. Second, a request typically consumes system resources, such as threads, database connections. If there are a large number of waiting requests, it may exhaust system resources, causing application downtime or performance degradation. Ending the request early can release system resources as quickly as possible. The following is the program. It sets the timeout in the context and uses the channel selector to determine the result of the operation. When timed out, the channel of ctx is closed (ctx.Done()), the function stops running, and cancelFunc() is called to stop the downstream operation. If the timeout is not reached, the program completes normally.
|
|
So should this feature be set on the client side or server side? For service retry, there is no problem and it can only be set on the client side. The service timeout can be set on both the server and the client side, but it is better to set it on the client side, so the fate is in your own hands.
The next question is the ordering. Are you doing service retry first or service timeout first? The result is different. When doing a service retry first, the timeout is set on all retry attempts; when doing the service timeout first, the timeout is set on each retry. Which one to choose depends on your specific needs. I set the timeout on every retry.
Rate Limiting:
Rate limiting sets an upper limit on the number of requests based on the capabilities of the service, typically the number of requests per second. After that, all other requests return an error message. This guarantees the quality of the service, and even the requests won’t be served can get the results back quickly. This feature is different from the others, it is defined on the server side. Of course, you can also limit the number on the client side, but in the end you have to limit it on the server as well.
The following is the “cacheServer.go” in the server side “service” package, which defines the interface of the server. “CacheService” is its struct, which implements the “Get” function, which is the business logic of the server. All other decorators are complementary to it.
|
|
The following is “serverMiddleware.go”, which is the entry point for the server middleware. It defines the struct “CacheServiceMiddleware”, which has only one member “Next”, and its type is “pb.CacheServiceServer”, which is the interface of the gRPC server. Here we handled server side code differently from the client side. Instead of creating another interface, we used the server interface of gRPC directly. We created an interface for each function on the client side, so that the granularity of the control is finer, but the amount of code is larger. On the other handle, all functions on the server share one interface, the granularity of the control is coarser, but the amount of code is smaller. The reason for this is that the client needs preciser control. You can decide which strategy to choose according to the needs of the application. “BuildGetMiddleware” is a function that creates decorated structs on the server side. ThrottleMiddleware is the implementation struct of rate limiting. There is only one member “Next” in it. When you create the chain of middleware, you need to pass in them in turn and here we only have one, “ThrottleMiddleware”.
|
|
The following is the implementation of rate limiting, which is slightly more complicated than the other functions. The control parameters used by other functions (such as the number of retries) are not modified during execution. In rate limiting, throttle can be read and written in parallel, so it needs to be controlled by “sync.RWMutex”. The logic of rate limiting is in the “Get” function. It first checks if the threshold is exceeded; If exceeded, it returns an error message, otherwise it proceeds to run the underlying function.
|
|
Circuit Breaker:
The Circuit Breaker is the most complicated. Its main function is to block the service when the system detects that the downstream service is not available, thus reducing the load on the downstream service, and allowing it to recover. Related to it is the service downgrade. Generally speaking, a degrading function is defined, either by taking old data from the cache or directly returning a null value to the upstream function.
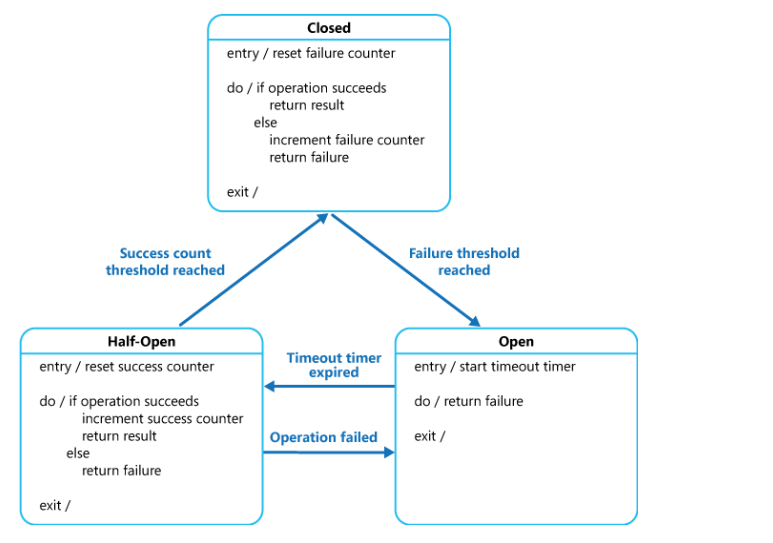
The Circuit Breaker is managed by the State Machine, which monitors the failure of the calls to the downstream service to control the circuit by a failure threshold. It has three states: closed, open, and half open. The “closed” here is the close of the Circuit Breaker and the service is open.
Normally, the Circuit Breaker is turned off. When the number of failed requests exceeds the threshold, the Circuit Breaker is turned on and the downstream service is turned off. There is a time limit for the Circuit Breaker to keep open, after which it automatically turns into a half-open state. In this state, only a small number of requests are allowed to pass. When the requests fail, it returns to the open state. When the number of successful requests exceeds the threshold, the Circuit Breaker is closed and the service returns to normal. The following is the diagram of it.
When there are multiple decorator functions, at first glance, it seems that the Circuit Breaker should be the first one to execute. Because if the service has a problem, there is no reason to try others, such as service retry. However, if we are doing that, then the retry is not going through the Circuit Breaker, so the Circuit Breaker actually should be the last one. It is also determined by what decorating features you have.
There are many different implementations of the Circuit Breaker, the most famous one is Netflix’s “Hystrix”. I used a Go open source library called gobreaker, because it is simple and pure (Hystrix integrates many features together besides the Circuit Breaker). The following is the code for it. The “cb” is the instance of “CircuitBreaker”, which is created in “init()” so that it is created only once. When created, several parameters are set. “MaxRequests” is the maximum number of requests allowed to pass through in the half-open state. “Timeout” is the timeout period of the closed state (automatically turned into half-open after the timeout), which is not set here (The default value is 60 seconds). The “ReadyToTrip” function is used to control state transitions. When it returns true, the Circuit Breaker changes from off to on. The implementation code is in “CallGet”, and “cb.Execute” will execute the function passed in. If the Circuit Breaker is on, it returns the default value without calling downstream function, otherwise it executes the request as normal. The Circuit Breaker monitors the execution status of the requests and controls the switching based on the status.
|
|
In this example, the Circuit Breaker is set on the client side and monitors the request on the client side. But I think it is actually better to monitor the status on the server side. Because most of the problems that Circuit Breaker want to deal with is service downtime, so monitoring the server is more efficient than monitoring the client. Of course, the final action is still to shield the client requests to reduce the service load. Then it needs the coordination between the server and the client, so it is more difficult to do.
Another problem is how to judge that the service is down. This is the key to the feature. If the service call returns an error, does it mean that the service is unavailable? It seems the server need to return a service unavailable error, which can include rate limiting exceeding and timeout error. Also, the client needs to have a timeout as well. Only those errors lead to service down.
Fault Injection
Fault injection simulates various faults and instabilities in a production environment by artificially injecting errors. You can simulate a 10% error rate, or a service response delay. The technique used is similar to what’s described above. The service request can be monitored and controlled by applying the Decorator Pattern to achieve the purpose of simulating errors. Fault injection can be implemented either on the server side or on the client side.
Bulkhead
Bulkhead isolation technology refers to the isolation of system resources so that when a request fails, it does not bring down the entire system. The more common ones are the isolation of the Thread pool and the Connection pool.
For example, if requests exceed the database connection limit, then all new requests will be in the wait state. If your system has both slow-running requests (such as reports) and fast-running requests (such as modifying a database field),
then a good way is to set up two Connection Pools, one for the faster one and one for the slower one. This way, even when the slow requests occupy all the slow connections, it does not affect the fast requests. The following is a diagram of it, which uses the Thread Pool as an example.
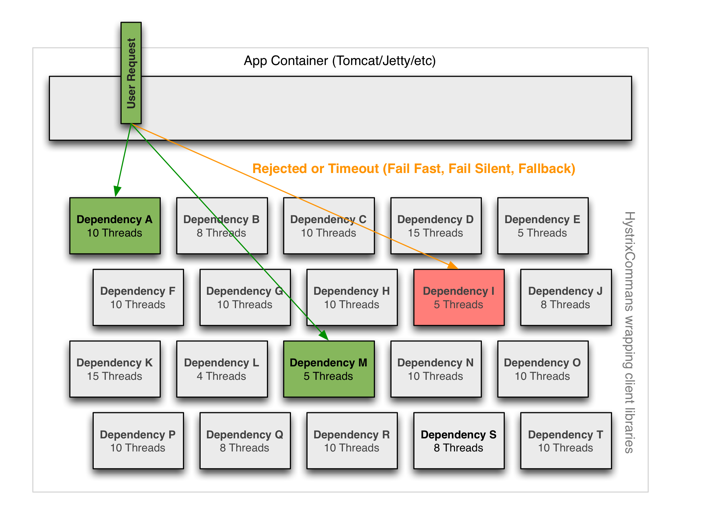
Netflix’s Hystrix integrates both the bulkhead isolation technology and the Circuit breaker to achieve isolation by restricting access to a service’s resources (typically Thread). There are two ways to achieve it, the first is through the Thread Pool, and the second is Semaphore Isolation. For Semaphore Isolation, each request must be authorized to access the resource. For details, please refer to “How it works” for detail.
The practical application of bulkhead isolation is much broader than that of Hystrix. Bulkhead isolation is not restricted to one area, but can be applied in many different directions (read here for details) .
Adaptive Concurrency Limit
The techniques described above are based on static thresholds, most of which are requests per second. But for large distributed systems with Auto-scaling, this approach may not apply. The automatically scaled cloud system adjusts the number of servers based on the service load so that the threshold of the service becomes dynamic rather than static. Netflix’s next-generation technology builds dynamic thresholds called Adaptive Concurrency Limit. Its principle is to calculate the load based on the delay of the service, thereby dynamically finding the threshold of the service. Once the dynamic threshold is found, this technique is easy to be applied, and the hard part is how to figure out the threshold. This technique can be applied in the following areas:
- RPC (gRPC): Can be applied to both the client side and the server side and can be implemented using an interceptor.
- Servlet: Can be implemented using filters.
- Thread Pool: It automatically adjusts the size of the Thread Pool based on the service delay to achieve concurrency limits.
Please refer Netflix/concurrency-limits for details.
Implementation by Service Mesh:
As can be seen from the above code implementation, each of the features is not complicated and does not intrude on business logic. But we only implemented service resilience for one function. If you have many Microservices, which have many functions, then you have a lot of code to write. How to simplify it? When I first encountered the service resilience, I used the Interceptor to make the code not intrusive. But it is not flexible enough until I found the Decorator Pattern. But the workload is still quite large. Finally, Service Mesh came to the rescue. Because most of the problems and solutions of service resilience are related to infrastructure, it is better to leave them to infrastructure rather than code. This should relief application code from those burdens and focus back on business logic.
The emergence of container technologies (Docker and Kubernetes) greatly simplified the deployment of applications, especially Microservices. But initially, the service resilience is still archived by the application code. The most famous one is “Netflix OSS”. Now we have extracted those features out of application code and passed them to Service Mesh, of which the popular ones are Istio and Linkerd. By manipulating service requests, Service Mesh gained granular control of applications, while on the contrary the container can only control on the service level.
When using Service Mesh to achieve service resilience, you only need to write some configuration files instead of coding. But it is not without its shortcomings. Writing a configuration file is another way of coding, which is error-prone when the file is large. There are already better IDEs that support container, but support for Service Mesh is not ideal. Service Mesh definitely has a bright future, and maybe it will be integrated into the container technology and become part of it in the future.
When do you need it?
No matter how you implement Service Resilience, there is a lot of work to do, especially when there are many services and the calling relationships are complex. So should you make all services having these features? My suggestion is to add these features to the most important services initially, while leaving other services for later consideration. After you deployed the application to the production environment for a period of time, you would have a better idea on which services are problematic, and then decide what to do next. The benefit of applying the Decorator Pattern is that you can add or remove decorators without affecting the business logic code.
Conclusion:
Service resilience is a very important technology in Microservices. It makes the service still available when the environment is unreliable, thus greatly improving the resilience of services. Technologies used include Timeouts, Retry, Rate Limiting, Circuit Breaker, Fault Injection, and Bulkhead. You can implement these features by code or Service Mash. Service Mesh is the future direction. But implementing them requires a lot of work, so you need to choose which services to apply the technology.
Source Code:
The complete code is in github: https://github.com/jfeng45/grpcservice
Reference:
[1]Go kit http://gokit.io/examples/stringsvc.html
[2] Circuit Breaker Pattern https://docs.microsoft.com/en-us/azure/architecture/patterns/circuit-breaker
[3]gobreaker https://github.com/sony/gobreaker
[4]Bulkhead pattern https://docs.microsoft.com/en-us/azure/architecture/patterns/bulkhead
[5]How it Works https://github.com/Netflix/Hystrix/wiki/How-it-Works
[6]It takes more than a Circuit Breaker to create a resilient application https://developers.redhat.com/blog/2017/05/16/it-takes-more-than-a-circuit-breaker-to-create-a-resilient-application/
[7]Netflix/concurrency-limits https://github.com/Netflix/concurrency-limits
[8]Istio] https://istio.io/
[9]Linkerd https://linkerd.io/
Translations
See also
- How to Do Tracing in Go Microservice?
- Go Microservice with Clean Architecture
- Go Microservice with Clean Architecture: Application Logging
- Go Microservice with Clean Architecture: Application Layout
- Go Microservice with Clean Architecture: Application Container